Introduction to HTTP
“The tunnels might long, and twisted, and dark, but you are supposed to go through them.” — Lauren Oliver
The world of the internet is based on requests and responses, All the nodes in the world wide web are interconnected and talk to each other without geographical and language boundaries. How does that happen? That’s where we need protocols! and HTTP is one of the most famous ones.
What is HTTP?
HTTP (HyperText Transfer Protocol) is a Protocol built to provide the ability to data transferring and resource fetching based on a client-server protocol. Here’s an example below

Here the user-agent (an application that initiates the request to the client on behalf of the end-user. Ex- Web browsers) requesting a web page from a web server. This single web page might connect and add hyperlinks to the different servers. HTTP will initiate the communication between these servers and get the requested content back to the client. and user agent(in this case web browser) will process them and display them to the user.
Before exploring the whole process Let’s just jump back to the history of HTTP first.
History of HTTP
HTTP is first started as a project of a CERN when Tim Berners invented the world wide web as a part of www on top of TCP/IP stack. HTTP is implemented to exchange HTML documents at that time.
At that time HTTP identified as the one-line protocol
HTTP 0.9
HTTP is very simple at that time the response only consist of one line and only the GET method followed by the path of the resource.
GET /index.htmlResponse as follows,
<html>
Welcome to my Web Page
</html>in HTTP 0.9 if there is an error, a separate message will be displayed to the user with the reason to fail but the user-agent does not know about the cause of the error or there was an error occurred.
HTTP 1.0
A major version released to address those issues and with this version
- starts supporting files more than the regular HTML files using the “Content-Type:” header (Ex —
text/html, multipart/form-data, application/json, text/xml). - In this version, the HTTP headers were introduced, making it easier to exchange metadata to be transmitted.
- In the previous version user only knows if there was an error but from the 1.0 version the user-agent can also know what is the error, what is the version of HTTP.
- HTTP 1.0 starts supporting not only the GET method but also HEAD and POST.
HTTP 1.0 GET request as below
GET /index.html HTTP/1.0
User-Agent: Mozilla/3.01 (X11; I; SunOS 5.4 sun4m)HTTP 1.0 response as below.
HTTP/1.0 200 OK
Date: Fri, 08 Aug 2003 08:12:31 GMT
Server: Apache/1.3.27 (Unix)
MIME-version: 1.0
Last-Modified: Fri, 01 Aug 2003 12:45:26 GMT
Content-Type: text/html
Content-Length: 2345
<HTML>
<img src = "logo.jpg">
Welcome to the Blog
</HTML>But there was a major problem in both the HTTP 0.9 and 1.0 and this cause a performance drawback of communicating. both of these versions open a connection and closed the connection as soon as the request completes. For each request, a new connection should be initiated. hence the HTTP based on the TCP layer before communicating the three-way handshake should be also carried out.
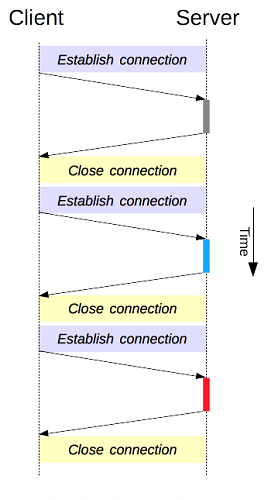
As you can see for each request-response it does the handshake, opens a separate connection, serves the response, handshake again, and closes. this is a time and resource-consuming process. Let’s now come back to the past!
HTTP/1.1
After addressing the problems a new version of HTTP 1.1 release as a minor version in early 1997 and currently widely using till now.
- The need of opening and closing multiple connections is eliminated by allowing the connection to be reused. This is by adding
Connection:header and set it to thekeep-alive(Ex:Connection: keep-alive) - From HTTP/1.1 Multiple methods are beginning to support such as,
GET,HEAD,POST,PUT,DELETE,TRACE,OPTIONS - Using
Hostheader server provides the capability to add different domain names into the same IP address
Host: <host>:<port>Example -
Host: blog.mywebsite.com:8081
Host: mywebsite.com
- HTTP/1.1 performance into a priority and added improvements such as pipelining, Chunked responses, and additional caching mechanisms.
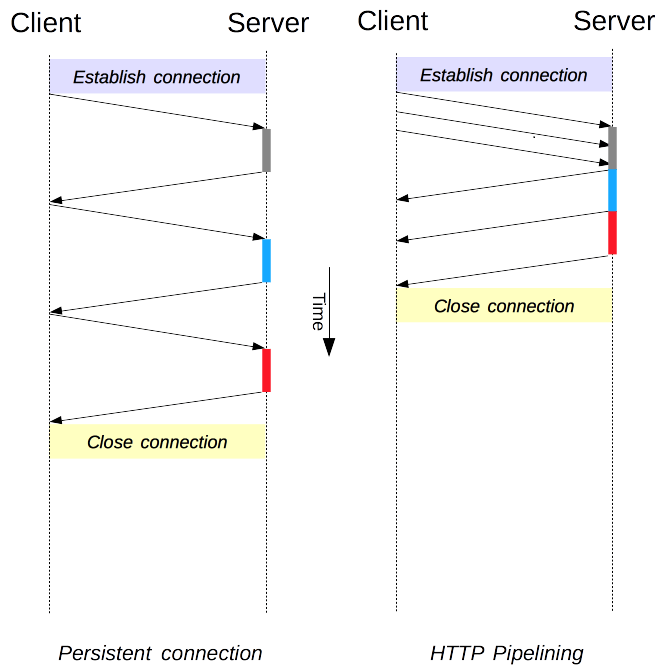
Using HTTPS
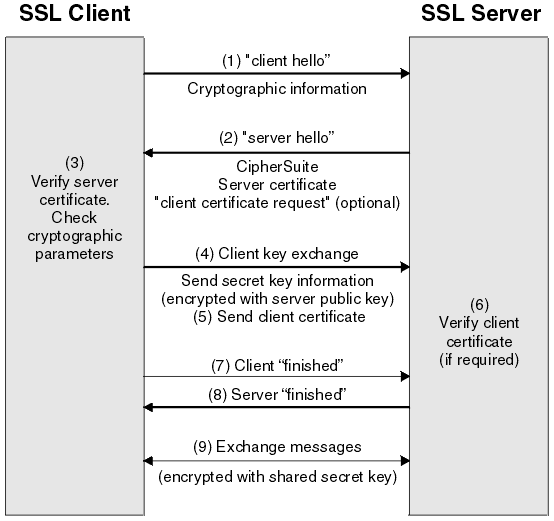
At the end of 1994 instead of sending traffic over a basic TCP/IP stack. Netscape Technologies integrated an additional secured transmission layer on top of it. After the SSL (Secure Socket Layer) 3. it changed as SSL/TLS
TLS provides safe communication between the client and server by bidirectional encrypting the data, because of this there is a way of intervening between the connection and carry out MitM Attacks.
Future of HTTP - HTTP/2.0 And Beyond
The world wide web keeps evolving the web applications are now getting more complex and increasing its capabilities and also load making the data amount to be transmit getting higher and higher, Then there are enough reasons for a better solution
The foundation of the HTTP/2.0 begins with the Google’s implementation of an experimental protocol named “SPDY” (pronounced as “Speedy”). It showed an increase in the responsiveness and solution for the data duplication at the transmission. Based on that there are few improvements in HTTP/2.0.
- HTTP/2.0 is a binary protocol rather than exchanging texts.
- It’s a multiplexed protocol, Parallel requests can be handled over the same connection, and unlike HTTP/1.x, it does not order and blocking constraints.
- It compresses headers. As these are often similar among a set of requests, this removes duplication and overhead of data transmitted.
- It allows a server to populate data in a client cache, in advance of it being required, through a mechanism called the server push.
HTTP/2.0 was standardized in May 2015, and by July 2018, 8.7% of all the websites at that time were migrated to the HTTP/2.0.
This is a non-stop process the evolution keeps going on, even for the HTTP/2.0 version there are few fixes including Cookie the header which guarantees Cookies are not altered, Client-Hintsprovides the ability to user-agent communicate about requirements and hardware constraints on the server and Alt-Svc allows finding the dissociation of the identification and the location of a given resource, allowing for a smarter CDN caching mechanism.
And in the meantime, HTTP/3.0 is in implementation! by replacing a new transport protocol called “QUIC”. find out about that more here.
Underlying Technology of the Communication
We talked about HTTP and how it works in an architectural and implementation approach, But how it actually works through this world of networks?
From establishing the connection, communication network protocols should have to follow an architectural approach to provide service without collusion.
At the early times of the Internet and Networks are invented different vendors of implementing network equipment and organizations tend to have their own technologies and protocols so there was a need for standardization for network communication.
As a solution ISO introduced a conceptual model called OSI(Open System Interconnection) Model architecture with 7 layers for standardizing the communication.
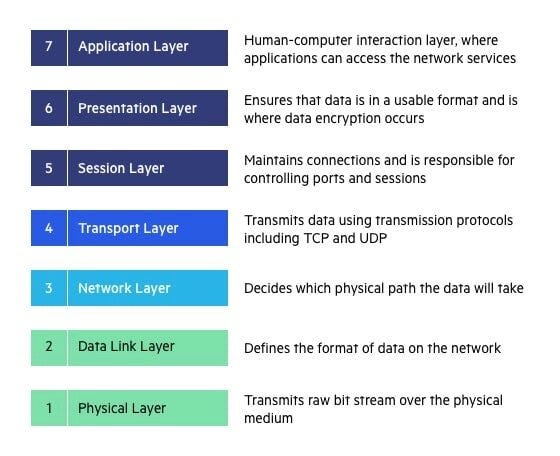
Now let’s see how HTTP requests flow through the OSI layer.
Physical Layer - This layer engages with the bits of raw data receiving from the other ends or sending raw data to the receiver.
Data Link Layer - This layer ensures that the receiving data are free of undetected transmission errors. How it does it breaks the upcoming data into the data frames and each data frame will receive an acknowledgment frame.
Network Layer - This layer decided how the packet should be moving from one location to another using the best path.
Transport Layer - Transport Layer manages the delivery of the data packets and ensuring that they are free of errors and it has the sequence in the correct order and there are no duplications.
Session Layer - The session layer establishes the communication after the process of authentication and authorization if the data is unauthorized it will terminate the session.
Presentation Layer - The Presentation Layer reads the information about the headers and will decrypt the data so the layer above can view it.
Application Layer - Through a user agent or CLI user will view the data in an appropriate manner and synchronize the communication
